
De oorzaken van je ‘untidy data’
“It is often said that 80% of data analysis is spent on the process of cleaning and preparing the data” (Dasu and Johnson 2003). Twee keer raden waar ik al veel tijd aan besteed heb? Jawel, “cleaning and preparing data”.
Er is een bijzonder relevante paper, die iedereen moet lezen, over de problemen die er bestaan in “untidy data” en de oplossing om tot “tidy data” te komen. Hier wil ik het hebben over de oorzaken van “untidy data”. Het is namelijk belangrijk te begrijpen waar de problemen in de data vandaan komen, zodat we er structureel iets aan kunnen doen. No more untidy data?
De Freakonomics Fallacy
Het ideaal van “tidy data” is volgens mij geïnspireerd door de datasets die beschreven worden in gestandaardiseerde experimenten. In zulke experimenten worden metingen gedaan die een zeer concreet geformuleerde onderzoeksvraag moeten beantwoorden. Door de traditie die het experiment met zich mee draagt, weet ook iedereen welk type van onderzoeksvragen beantwoord kunnen worden. Data en inzicht staan al vanaf stap 1 op gelijke hoogte.
Dit soort van experimenten ken ik vanuit mijn onderzoeksachtergrond vooral in de psychologie, neurologie, taalverwerving, etc. Typisch is ook dat de “meetinstrumenten” vaak dezelfde zijn, bv. eye tracking, reactiesnelheden, etc. En vaak worden de onderzoeksvragen afgestemd op de mogelijkheden en tekortkomingen van de meetinstrumenten. Dit maakt allemaal deel uit van het experimental design.
Het ontbreken van een realistische planning en inhoudelijke voorbereiding van de dataverzameling en de onderzoeksvragen is één van de oorzaken voor “untidy data”.
De titel van deze paragraaf is “de freakonomics fallacy”, omdat het populaire boek van een aantal jaar geleden de indruk geeft dat er voor elke interessante vraag ook wel ergens een dataset ligt die het inzicht kan onderbouwen. Dat is natuurlijk nogal misleidend.

In de simpelste en ideale vorm lijkt gegevensgebaseerd onderzoek een rechte lijn te zijn tussen vraag en antwoord, via data. De realiteit is anders.
Voortschrijdend inzicht
Uiteraard is de neerslag van een experiment in een paper een geïdealiseerde vorm van het eigenlijke onderzoeksproces. De realiteit is dat het onderzoek de hele tijd heen en weer gaat tussen nadenken over de onderzoeksvraag, het meetinstrument en de interpretatie van de metingen. De “tidy data” waar we mee geconfronteerd worden in mooie papers zijn vaak ook de eindproducten van een lang proces. Dat proces houdt in dat je begint met metingen, maar vaststelt dat het toch niet echt je onderzoeksvraag beantwoord. Je verandert het meetinstrument, de onderzoeksvraag wordt licht aangepast, je ontdekt een ander interessant probleem, … In de ondernemerswereld heet dit wel eens “pivoteren”. Dit is een heel natuurlijk proces, maar het is belangrijk te snappen dat dit een impact heeft op je data. Be aware!
De realiteit van meanderende onderzoeksvragen en “vooruitschrijdend” inzicht op basis van data exploratie is een eerste, natuurlijke oorzaak voor “untidy data”.
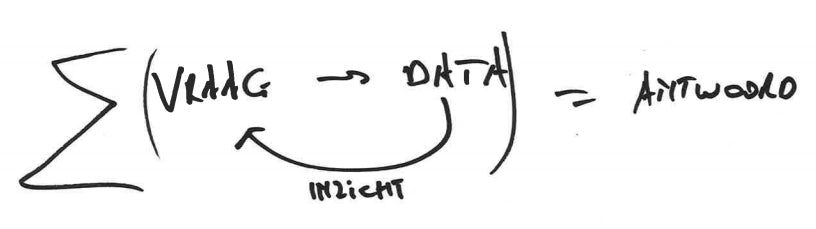
In tegenstelling tot het schema hierboven is een antwoord eerder de som van inzichten die ontstaan tijdens het heen en weer schipperen tussen vraag en data.
In Freakonomics wordt dit aspect van data-gerelateerd onderzoek helemaal geminimaliseerd. Er wordt onmiddellijk van de onderzoeksvraag naar de resultaten gesprongen. Dat is prima vanuit journalistieke overwegingen, maar we mogen ons daar als onderzoekers of als inhoudelijke experten niet door laten misleiden.
Opportunist
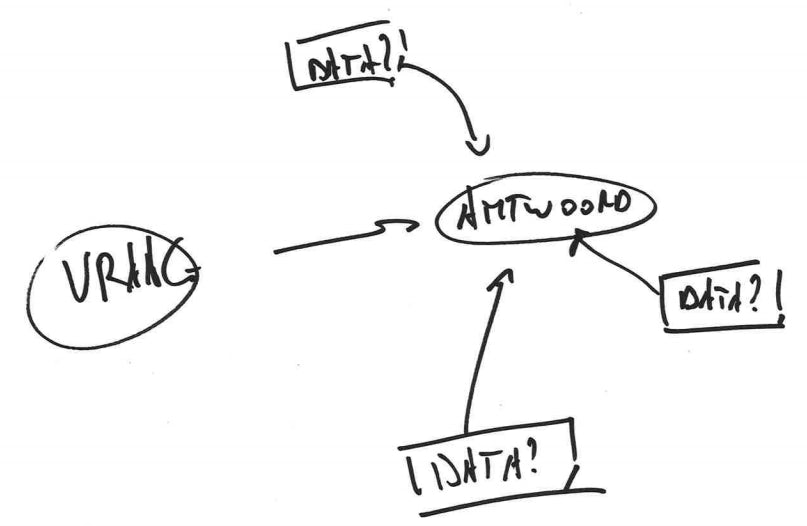
Hierboven gaan we er nog van uit dat er een onderzoeksvraag en een bijhorend meetinstrument is. De realiteit is echter dat vaak één van beide ontbreken. Een onderzoeksvraag wordt gesteld, en dan gaan we met de beste bedoelingen op zoek naar bestaande datasets om relevante inzichten te bevestigen of te krijgen. Het logische probleem is dat de gegevens niet verzameld zijn met het oog op het beantwoorden van de onderzoeksvraag, waardoor die discrepantie moet opgelost worden door dataverrijking (feature construction): interpretaties, bewerkingen, hercategorisering, … Het is ook niet ongebruikelijk dat er een dataset gezocht wordt om een geprefereerd antwoord te onderbouwen.
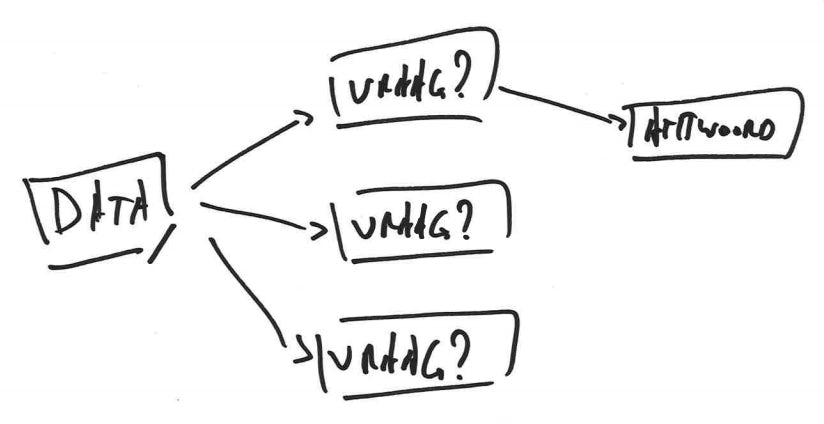
Omgekeerd, een dataset dient zich aan, zonder dat er een duidelijke onderzoeksvraag gesteld wordt. Het idee is dat “de data zelf zal tonen wat er interessant is”. Dit is een grote misvatting, die ook geslopen is in de entry “big data” van het glossarium van de visienota cultuur en digitalisering. Exploreren van data kan helpen om tot inzichten te komen, maar het gebeurt zelden dat een fundamenteel inzicht simpelweg opduikt uit de gegevens. Natuurlijk zijn er wel exploratieve methodes die inhoudelijke experten kunnen bijstaan om patronen te ontdekken.
Het opportunistisch combineren van bestaande datasets met nieuwe onderzoeksvragen vergt verregaande manipulatie van de voorliggende gegevens, en dat is een tweede oorzaak voor “untidy data”.
Gegevensverzameling gaat best hand in hand met gegevensanalyse. Als er verzameld wordt met het doel bepaalde onderzoeksvragen te kunnen beantwoorden, dan is dat vele male “efficiënter” dan verzamelen “for the sake of collecting data”. Gegevens die verzameld worden zonder onderzoeksvraag in het verschiet belanden uiteindelijk op een data-kerkhof. Zo ook voor de mensen die verzamelen, trouwens: niets is demotiverender dan gegevens in databanken steken zonder dat er iets mee gebeurt. We horen wel eens de term “planlast”.
Wat we zelf doen, doen we beter
Tot slot moeten we ook nog kijken naar het meetinstrument zelf. We moeten een onderscheid maken tussen data die we zelf verzamelen in een gecontroleerde omgeving, versus “gerapporteerde” data.
Feitelijk is dit de aloude problematiek van “crowdsourced” data. Het gebruiken van de “wisdom of de crowds” is efficiënt omdat er snel veel data bij elkaar gebracht worden, maar de prijs die je betaalt is dat er meer moeite moet gestopt worden in het waarborgen van de kwaliteit van de gegevens.
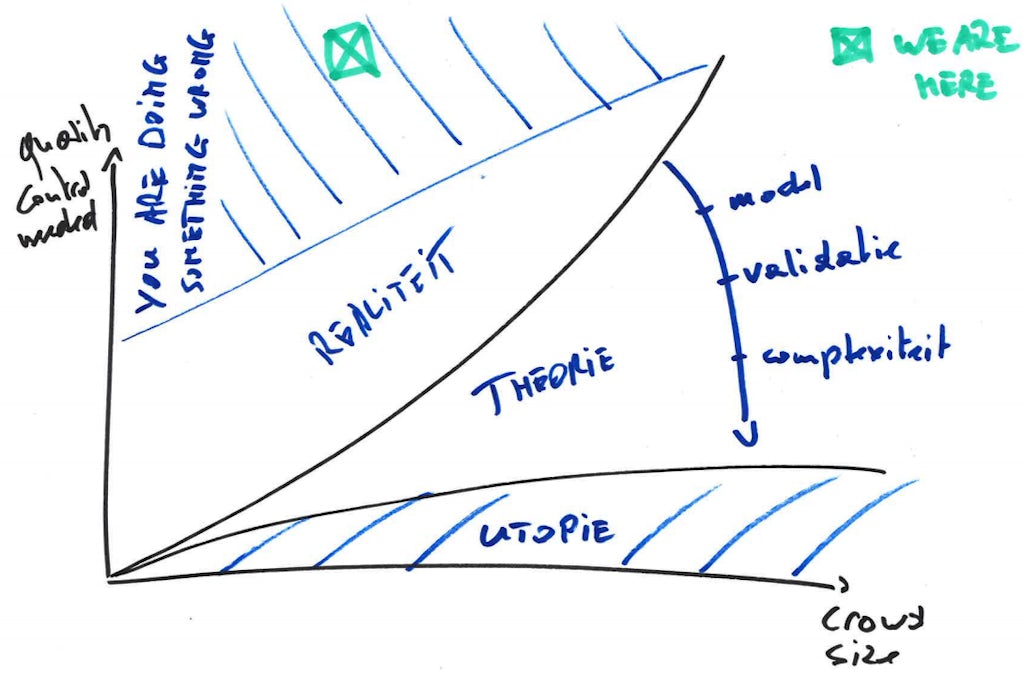
Als we ons even permitteren om die problematiek als gimmick in een modelletje te gieten, krijg je de figuur hierboven. Trouwens, wie aan dit schema uitkomt, chapeau :o). In theorie kan je de hoeveelheid kwaliteitscontrole naar beneden brengen door een helder data model te hanteren, voldoende validatie in de inputformulieren te voorzien, en de complexiteit van de in te voeren gegevens laag te houden.
Gegevens die worden ingevoerd door veel verschillende mensen, zonder daarbij voor een helder data model, strikte validatie en lage complexiteit te zorgen, leveren weliswaar veel data op, maar vereisen ook veel kwaliteitscontrole en opschoonwerk. Dit niet toepassen is de derde reden voor untidy data.
Conclusie
We identificeren dus drie belangrijke oorzaken voor untidy data:
- omdat data-gedreven onderzoek niet anders is dan kwalitatief onderzoek qua exploratief proces, kan je met untidy data komen te zitten als je niet goed de structuur van je datasets bewaakt
- een dataset die niet ontstaan is in het licht van je onderzoeksvraag vereist manipulatie, en de manier waarop je die manipulatie organiseert kan leiden tot untidy data
- als je data laat verzamelen door meerdere mensen, zelfs als er een concrete onderzoeksvraag voorligt, is er een grote kans dat je met untidy data te maken zal krijgen, als je niet voor een helder begrippenkader, strenge controle bij invoer, en een lage complexiteit zorgt.
De conclusie is dus eenvoudig. Verzamel gegevens liefst met het oog op specifieke onderzoeksvragen, hanteer een goed gestructureerd documentatieproces van de gegevensverzameling en verrijking die je onderneemt, en koppel nooit je gegevensverwerking los van je inhoudelijke expert!
