The making of Trending Topics, een inhoudsanalyse van het publieke debat over kunsten en cultuur
In het cijferboek van Kunstenpunt, dat op 15 oktober zal verschijnen, staat er een tekst waarin het publieke debat van de afgelopen 4.5 jaar gereconstrueerd wordt op basis van krantenartikels, tijdschriftartikels, standpunten van belangenbehartigers en vragen in de commissie cultuur. Deze blogtekst legt uit hoe die reconstructie tot stand kwam.
Waarom?
Misschien eerst: waarom zou je zo een debat willen reconstrueren? Wel, Kunstenpunt moet een Landschapstekening opleveren in september 2019 waarin de kunstensector beschreven wordt. Die beschrijving moet uiteraard onderbouwd zijn met cijfers en feiten. Om de vraag naar cijfers te beantwoorden maakte Kunstenpunt in de afgelopen jaren een hele bende aan cijferanalyses. Het oplijsten van feiten proberen we, onder meer, aan te pakken met deze reconstructie van het publieke debat. Dat alles komt samen in het cijferboek.
Dus, we gaan een overzicht maken van “alles met betrekking tot de kunsten” waarover er in de afgelopen 4.5 jaar geschreven is, distilleren daaruit de grotere thema’s, en voila, een eerste feitenbasis is geschapen. Makkelijk zat! Daarmee kunnen we dan (voor de landschapstekening) mee aan de slag om uit te spitten welke bewegingen en dynamieken aan de grondslag liggen van die thema’s. Tegelijk is het ook een opening om aan te geven welke thema’s niet of te weinig aandacht hebben gekregen.
Getting the data
De hele oefening hangt natuurlijk af van *tromgeroffel* data. Eerst probeerden we per introspectie een overzicht te maken van het publieke debat, maar al snel bleek dat we vooral recente thema’s bleken op te lijsten. Dat kan niet de bedoeling zijn, we wilden net een objectieve oefening maken!
Gelukkig kunnen we teruggrijpen op de dagelijkse persmonitoring van Kunstenpunt. Dat leverde een zicht op alle bronnen die in gopress.be gedeeld worden, met name de kranten en populaire tijdschriften. Maar daarmee hadden we nog geen goed zicht op de meer gespecialiseerde thema’s. Ik ging aan de slag met wat Python om te webscrapen: in geen tijd kon ik het archief van etcetera, (h)art, de witte raaf en rekto:verso “stelen” met een paar scriptjes. Van jazzmo(zaiek) en gonzocircus moest ik handmatig de inhoudstafels copypasten, maar dat was dan niet meer zoveel werk.
Elke website vereist een apart script en heeft een eigen logica. Hoewel deze automatisch oefening snel de individuele artikels kan downloaden zou het nog sneller en efficiënter gaan mocht er een heldere standaard zijn voor tijdschriftarchieven die ook daadwerkelijk gebruikt wordt.
Naast de algemene en gespecialiseerde tijdschriften zag ik ook nog wel brood in de standpunten van de belangenbehartigers. Enkel die van oKo waren makkelijk te screenscrapen. Van andere belangenbehartigers ging ik manueel door de lijst van standpunten.
Tot slot lag er nog een hele fijne te wachten: de vragen om uitleg in de commissie cultuur! En daar mag van gezegd worden: puike website! Zeer heldere structuur, en heel gemakkelijk te scrapen. Bij interesse, de python code staat online.
Goed, zo verzamelde ik eigenlijk vrij eenvoudig heel wat tekstmateriaal om het debat te reconstrueren. Maar de eerlijkheid gebied me om toe te geven dat ik niet kan beweren dat dit nu eens en voor altijd representatief is. Er ontbreken quasi alle online-only bronnen: posts op sociale media, blogs, online magazines, websites, … Ik besloot echter voor deze oefening dat vat niet open te trekken: met wat er geschreven is in de meer “established” bronnen zou ik al een eerste zicht moeten krijgen op wat er gezegd wordt, de diepgang en frequentie van die thema’s wordt natuurlijk gekleurd door het medium. Zo kan ik me prima voorstellen dat teksten over ecologie niet zo frequent in print verschijnen, net vanuit die ecologische gedachte.
Categorisatie
Met alle data verzameld kom je vanzelf uit bij het oude zeer van werken met data. Veel mensen denken dat data op zichzelf al een antwoord biedt, maar eigenlijk begint het dan pas.
Ik verzamelde om en bij de 40.000 artikels, maar met die grote hoop kan je niets aanvangen als er niet een beetje structuur in komt. Eerst dacht ik met een eenvoudige clusteralgoritme die structuur te ontdekken. Niet te moeilijk doen, en met een k-means of zo kom je al een heel eind.
Maar het blijkt dat ik niet voor alles een even goeie fulltext beschikbaar heb. De consequentie is dat stukken waarvoor ik enkel een titel heb, een vele sparsere vector zouden hebben in het kmeans algoritme, wat unfair zou zijn; er zijn namelijk wel een heel aantal stukken zonder fulltext (bv. jazzmo en gonzo!) en die a priori al uit de oefening laten zou niet verdedigbaar zijn.
Om dezelfde reden zou een semi-supervised methode niet werken: bv. eerst een aantal teksten handmatig categoriseren en dan met instance based learning de rest van de categorisatie automatiseren. Die aanpak werkte goed in het script dat ik maakte voor mijn oud-collega.
Er blijft dus maar 1 ding over: de handen uit de mouwen stropen. En dat kan ik. Recent nog verscheen mijn publicatie op basis van 70.000 twitter boodschappen. Dan zijn 40.000 artikeltjes een peulenschil!
Dus ging ik aan de slag op slapeloze momenten en tijdens dromerige treinreizen. Van de 40.000 artikels blijven er een goeie 3.000 over die een thematiek aanstippen die voorbij de waan van de dag gaan.
Visualisatie
Goed, teksten categoriseren en dan een grote tabel hebben is leuk, maar hoe breng je dit over naar een publiek? Een collega stelde onbesuisd voor om word clouds te maken. Die hebben we even op zijn plaats gezet, wat een idee!
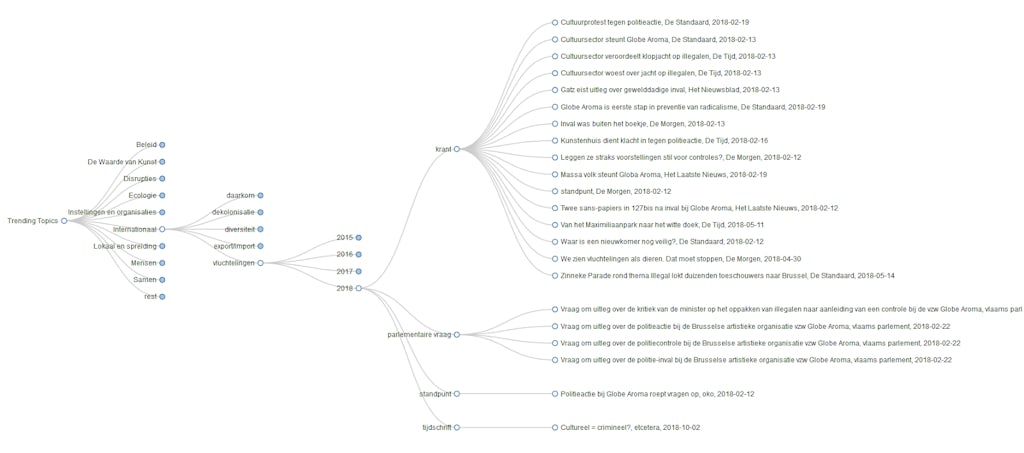
In plaats daarvan hebben nagedacht wat we willen bereiken. Aan de ene kant wil je een insteek in de data geven, en dus heb je een interactieve taxonomie nodig. Die maakten we hier met een beetje d3.
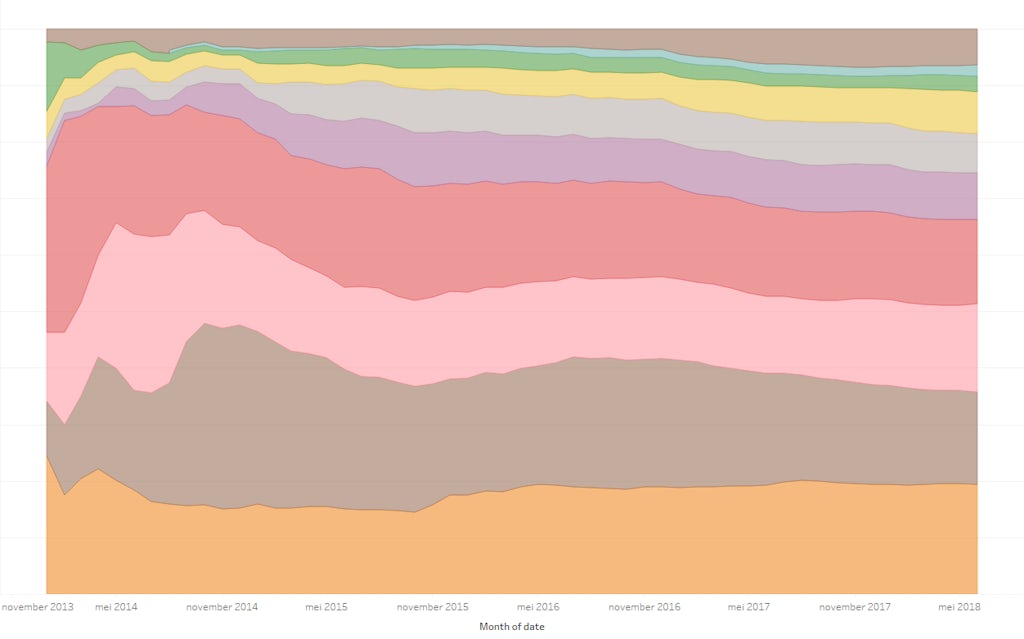
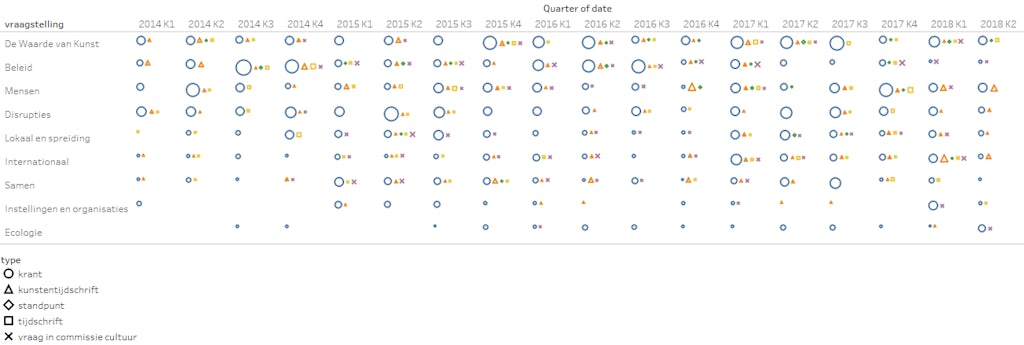
Daarnaast wil je laten zien hoe de verschillende thema’s doorheen de periode aan bod komen. Tegelijk wil je tonen in welke kanalen de artikels verschijnen. Hieronder geeft de vorm en kleur aan welk type van publicatie het was.
What’s next?
Ok, de analyse van de verschillende thema’s verschijnt als “Trending Topics” in het cijferboek op 15 oktober. Daarna gaat Kunstenpunt aan de slag om samen met de kunstensector tot een Landschapstekening te komen, niet in het minst door drie sectormomenten te organiseren. We hopen iedereen daar te mogen begroeten.